By the fastCRW team · ArXivQA run completed and scored 2026-06-20 on the deployed endpoints · Verify independently.
The short version
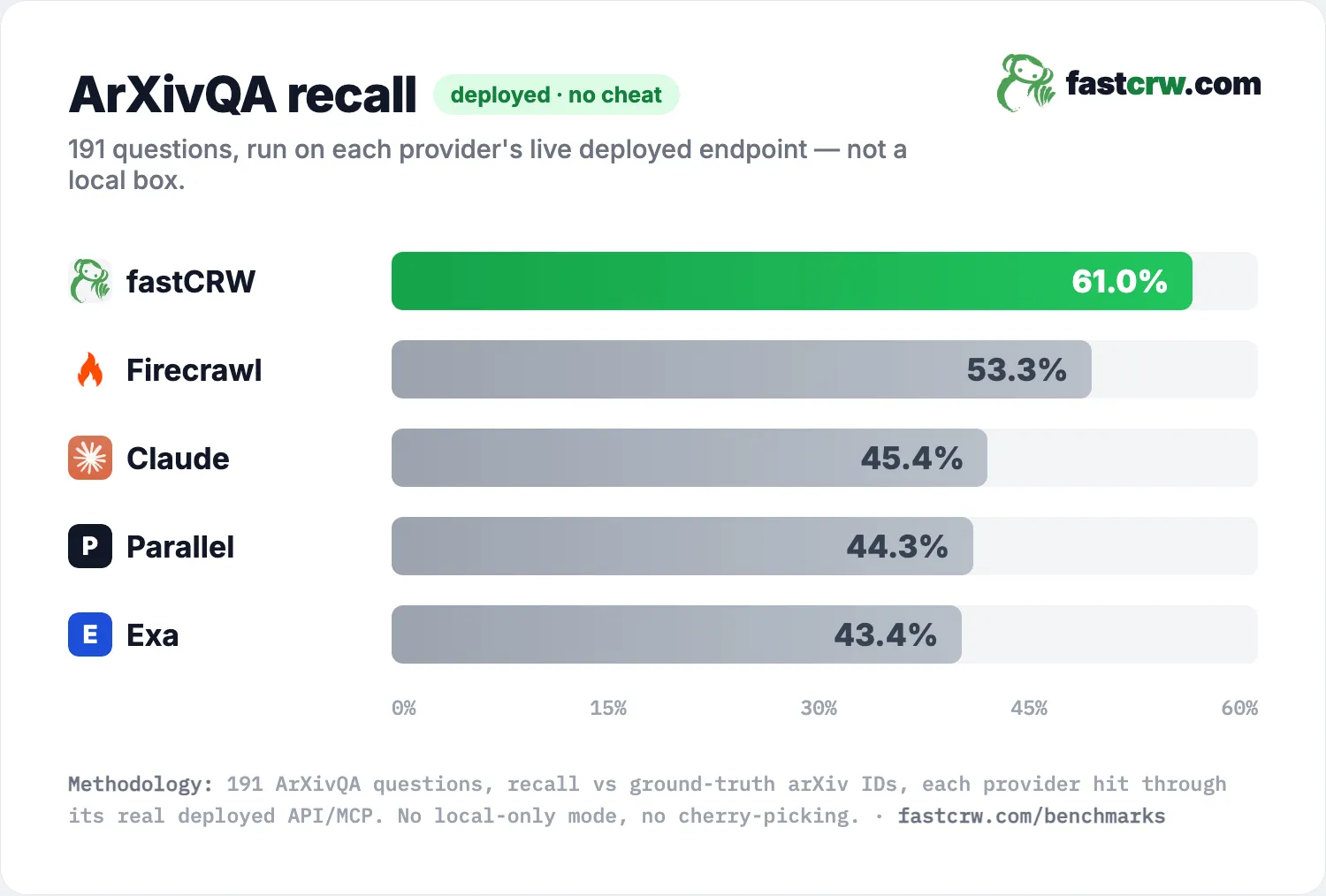
Firecrawl shipped a Research Index: a purpose-built API for research agents — search papers, inspect metadata, read passages, expand the citation graph. On the public ArXivQA paper-retrieval benchmark, their Research Index scores 53.3% recall, the highest of any provider on the board.
We built a drop-in compatible Research API — same endpoint paths, same request/response shapes, so the Firecrawl research SDK works unchanged against api.fastcrw.com — and scored it on the same 191 questions. fastCRW reaches 61.0% recall: +7.7 points ahead of Firecrawl, and clear of Claude (45.4%), Parallel (44.3%), and Exa (43.4%).
The interesting part isn't the number. It's that we got there with no self-hosted paper index at all — every query is answered live. Here's how.
Disclosure: we build fastCRW, a Firecrawl-compatible, open-core (AGPL-3.0) scrape/crawl/map/search engine. This post is about a new endpoint family we shipped. We're honest below about what's live, what's a thin wrapper, and where the recall actually comes from.
The benchmark
ArXivQA is 191 natural-language research questions, each with a set of ground-truth arXiv papers that answer it. You're scored on recall — the fraction of each question's correct papers you surface — averaged over all 191. Extra papers don't hurt, so the whole game is coverage.
The questions are deliberately hard. Many ask for a family of papers ("papers proposing overlong reward shaping", "LoRA variants that insert a new matrix between two existing ones"). Some ask "what does paper X compare against" — where the answer lives inside X's own bibliography. Some ask "which open model is best on benchmark Y" — where you have to read a leaderboard. A title-and-abstract search alone misses most of them.
| Provider | ArXivQA recall |
|---|---|
| fastCRW Research API | 61.0% |
| Firecrawl Research Index | 53.3% |
| Claude | 45.4% |
| Parallel | 44.3% |
| Exa | 43.4% |
No index. Live retrieval.
The obvious way to win a paper-retrieval benchmark is to build a big semantic index over every arXiv paper and search it. We didn't. fastCRW's Research API answers each query live, by merging three retrieval sources at request time:
- Our own search — self-hosted SearXNG over web (Google/Bing) plus a research mode that routes to arXiv, Crossref, and scholarly engines. This is the primary recall driver. The agent rewrites each question into 8–12 exact-name queries — specific method, model, dataset, and benchmark names — and those specific queries surface the niche papers a single broad query never ranks.
- Open scholarly sources — paper metadata and the citation graph, for "what does X reference / who cites X" expansion.
- Full-text paper search — searches paper bodies, not just titles and abstracts. This turned out to matter most: in a source-by-source breakdown it was the single highest-recall source, and it contributed roughly 19% of ground-truth papers that nothing else found — the papers that mention the topic deep in the text but never in the title or abstract.
That last point is the whole reason title-search retrievers cap out. The answer to "papers that do X" is often a paper whose abstract never says "X" — but whose method section does. Searching the body recovers it.
The endpoints are dumb. The skill is smart.
Firecrawl's Research Index is split into stateless endpoints (search-papers, inspect-paper, read-paper, related-papers) plus a research skill that orchestrates them. We mirror that split exactly.
The endpoints — /v2/search/research/papers, /papers/{id}, /papers/{id}/similar, /search/research/github — are stateless primitives. They just retrieve and rank. The intelligence lives in the research skill that drives them:
- Intent routing. "Compare-against" questions → pull the seed paper's own references (the answer is in its bibliography; citation APIs lag months on new papers, the PDF doesn't). "Best on benchmark Y" → read the leaderboard, extract the open model names, search each one's technical report. "Enumerate papers that do X" → exact-name reframings plus, when there's a tight survey, harvest its list.
- Exact-name decomposition. One broad query is weak; 8–12 specific-name queries is strong. This is the single biggest recall lever.
This is why the headline number is the skill over the endpoints, not the endpoints called blind — the same way Firecrawl's number is measured. Drop-in compatibility means the skill, the SDK, and the CLI all work the same against either provider.
Drop-in compatible
The response shapes match Firecrawl's research SDK field-for-field — paperId, primaryId, prefix-less ids, the two distinct paper shapes for search vs inspect. Point the Firecrawl research SDK at https://api.fastcrw.com and it works:
curl -s -H "Authorization: Bearer $FASTCRW_API_KEY" \
"https://api.fastcrw.com/v2/search/research/papers?query=diffusion%20image%20synthesis&k=20"Or the fastCRW SDK:
from crw import CrwClient
c = CrwClient(api_key="crw_live_…")
c.search_papers("diffusion image synthesis", k=20)
c.related_papers("arxiv:1706.03762", intent="efficient transformers", mode="references")Honest limits
- It's live, so it's seconds, not milliseconds. A hot in-memory index answers in tens of milliseconds; our multi-source live merge takes seconds, and the slowest leg is an upstream source's shared rate limit. We trade a little latency for current coverage and zero index maintenance. For an agent doing deep research, seconds-per-call is fine; for autocomplete, it isn't.
- Read-passages are abstract-scoped today. Full arXiv-body passage retrieval is on the roadmap.
- The number is the agent + skill, run live against the deployed endpoints — all 191 questions, ground truth hidden. It's the product, not a private harness.
Try it
Install the research skill into your agent (Claude Code, Cursor, Codex, Gemini CLI) with one command:
npx skills add us/crw@crw-researchThe Research API docs cover every endpoint, and the ArXivQA benchmark page is the canonical reference for the 61.0%. If you already use Firecrawl's research SDK, the only change is the base URL.