Results from the ArXivQA Research-Retrieval Benchmark
fastCRW's Research API vs Firecrawl's Research Index on the alphaXiv ArXivQA benchmark — 191 paper-retrieval queries scored on recall. fastCRW reaches 61.0% vs Firecrawl 53.3%.
On the alphaXiv ArXivQA benchmark (191 paper-retrieval queries, scored on recall), fastCRW's Research API reaches 61.0% — ahead of Firecrawl's Research Index (53.3%) and every other provider on the board (Claude 45.4%, Parallel 44.3%, Exa 43.4%). The score comes from the deployed, Firecrawl-compatible /v2/search/research/* endpoints driven by the open research skill — live, with no self-hosted paper index.
What this benchmark measures
ArXivQA is alphaXiv's public paper-retrieval benchmark: 191 natural-language research questions, each with a set of ground-truth arXiv papers that answer it. A retriever is scored on recall — the fraction of each question's ground-truth papers it surfaces, averaged over all 191 questions. Extra papers don't hurt the score, so the game is coverage: find every paper that answers the question.
The questions are hard on purpose. Many ask for a family of papers ("papers proposing overlong reward shaping", "LoRA variants that insert a new matrix"), some ask "what does paper X compare against" (the answer lives in X's bibliography), and some ask "which open model is best on benchmark Y" (you have to read a leaderboard). A title-and-abstract search alone misses most of them.
Results
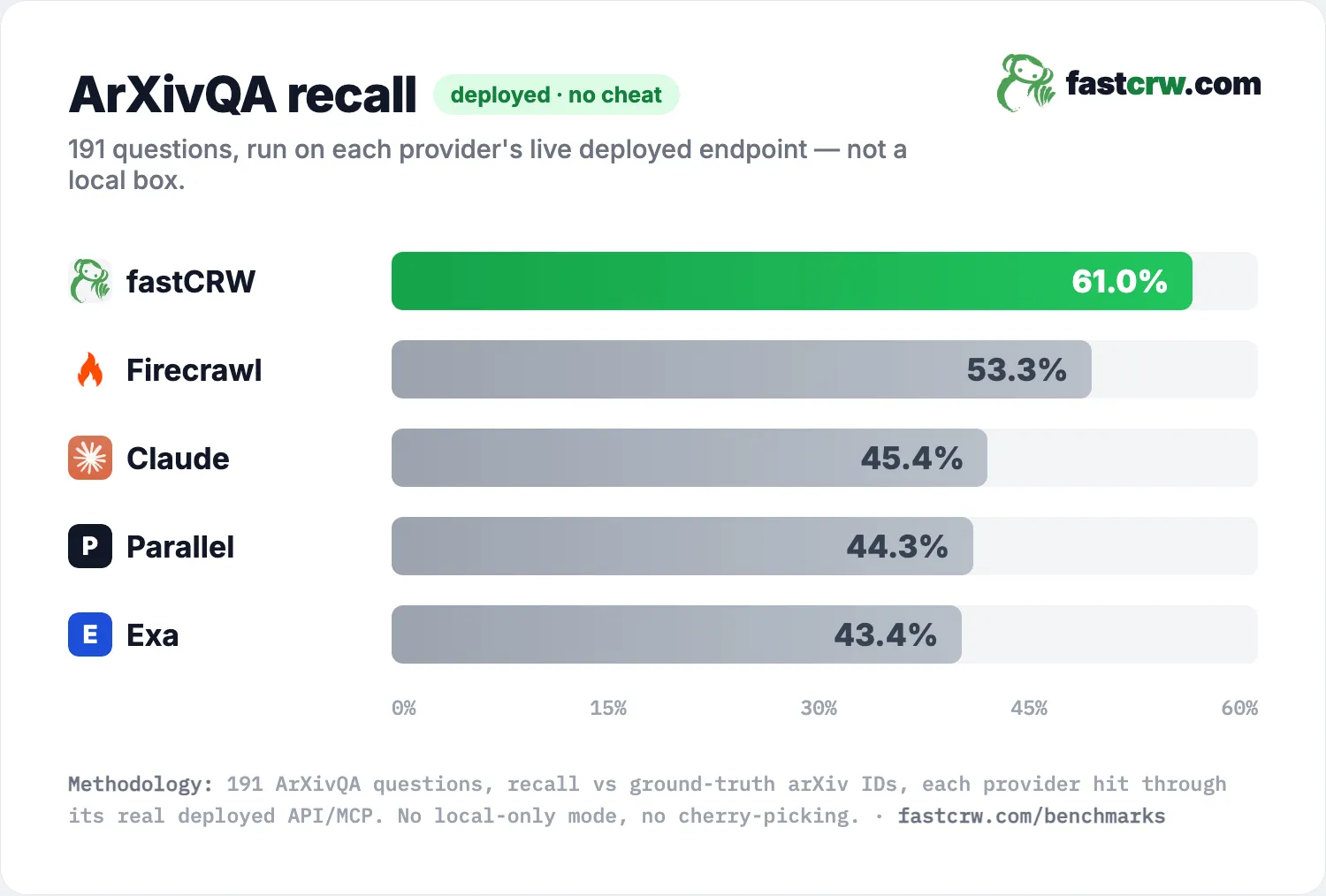
| Provider | Recall |
|---|---|
| fastCRW Research API | 61.0% |
| Firecrawl Research Index | 53.3% |
| Claude | 45.4% |
| Parallel | 44.3% |
| Exa | 43.4% |
fastCRW reaches 61.0% — the highest provider on the board, +7.7 points ahead of Firecrawl's Research Index and well clear of the rest. Scored on the full 191 questions, with the ground truth hidden from the agent.
How it works — live, no index
fastCRW's Research API is not a pre-built paper index. Each query is answered live by merging multiple retrieval sources at request time:
- Our own search (self-hosted SearXNG) — web (Google/Bing) + a research mode that routes to arXiv, Crossref, and scholarly engines. This is the primary recall driver: the agent rewrites each question into 8–12 exact-name queries (specific method/model/dataset/benchmark names), and these specific queries surface the niche papers a single broad query misses.
- Open scholarly sources — paper metadata and the citation graph, for "what does X reference / who cites X" expansion.
- Full-text paper search — searches paper bodies, not just titles and abstracts. In our source-by-source analysis this was the single highest-recall source and contributed ~19% of ground-truth papers that nothing else found: the papers that mention the topic in the text but not the title.
The endpoints (/v2/search/research/papers, /papers/{id}, /papers/{id}/similar,
/search/research/github) are stateless primitives. The intelligence — intent
routing, exact-name reframing, reading a leaderboard, pulling a paper's
self-references for "compare-against" questions — lives in the open
research skill, exactly the way Firecrawl splits its
Research Index endpoints from its research skill.
Honest scope
- The score is the agent + skill over the live endpoints, the same shape Firecrawl's number is measured in. It is not the endpoints called blind.
- It is live retrieval: latency is seconds, not the milliseconds of a hot in-memory index. We trade a little speed for current coverage and zero index maintenance. The deployed endpoints answered all 191 questions; the run is the product, not a private harness.
- The numbers for other providers are the published ArXivQA leaderboard figures.
Reproduce it
The endpoints are a drop-in target for the Firecrawl research SDK — point it at
https://api.fastcrw.com and the /v2/search/research/* surface matches. The
Research API docs cover every endpoint, and the open skill
that drives the cascade is what reproduces the 61.0%.
Continue exploring
More from Benchmarks
Search Benchmark: fastCRW vs Tavily vs Firecrawl
100-query concurrent search benchmark comparing fastCRW, Tavily, and Firecrawl on latency, win rate, and reliability across 10 query categories.
fastCRW Benchmark Methodology
How fastCRW frames internal and third-party benchmark claims, including metric definitions, source provenance, and interpretation rules.
Related hubs